
Bence, Azure Machine Learning Studio, Jupyter Notebook'dan sonra bu dünyaya adım atanların öğrenmesi gereken platformaların başında gelir. Neden böyle düşünüyorum? Çünkü işin mantığını kuş uçuşu bir şekilde hiç koda bulaştırmadan sürükle bırak yöntemi ile gösterme yeteneğine sahip. Bu dünyaya yeni adım atacak kişilere, "bak veriyi aldık", "temizledik", "öğrettik" şeklinde akış üzerinde gösterme ve her adımda veriyi görselleştirme imkânı tanıyor. Peki, bu ürün ilk ve tek mi? Değil, piyasada akış diyagramları şeklinde çalışan bir çok ürün bulunmakta -"KNIME" benim tercih diğer bir ürün mesela. Bu ürünü farklı yapan ise Azure'dan başkası değil. Azure ekosisteminden fevkalade faydalanabiliyorsunuz. Ürünleriniz, verileriniz Azure'da ise ürünü seçmenin mantığı giderek artıyor. Ben bu ürünü prototipleme, algoritmaları anlama veya diğer makine öğrenmesi araçlarında kurguladığım bir senaryonun sağlamasını yapmak için kullanıyorum ve bir ücret ödemiyorum. Ticari kullanımda doğal olarak ürünün fiyatlandırması devreye girecektir. Tam burada işinizin yapısına bağlı olarak diğer ürünlere kaçmanız gerekebilir.
İlk Adımlar
Ürüne ulaşacağımız adres :https://studio.azureml.net/ ; akabinde my experiments düğmesine basıyoruz. İşlemi yapınca açılacak sayfada bizi aşağıdaki gibi diyalog karşılayacak.
Bu diyalog penceresinden Take Tour'u seçerek temel işleri nasıl yapacağınızı hızlıca gösteren bir yönlendirici ile karşılaşacaksınız. Ben de yönlendiricinin yaptığı adımların bire bir aynısı ile başlayacağım. Çünkü bu adımlar işin abecesi. Farklı veri seti ile de çalışsak bireberi aynı işi yapacaktık. Aynı olan adımlarda tura ek olarak hangi adımda neyi neden yaptığımızdan bahsedeceğim ve ardından turun devamına serberst olarak devam edeceğim.
Tura başlayalım
Yeni bir deney oluşturarak işe başlayacağız. Bu deneyde amaç kişilere ait bilgilerden onların maaşlarının 50bin'den az mı fazla mı olduğunu tahmin etmek olacak. Bunun için arayüzün sol alt kısmından new düğmesine basıyoruz.
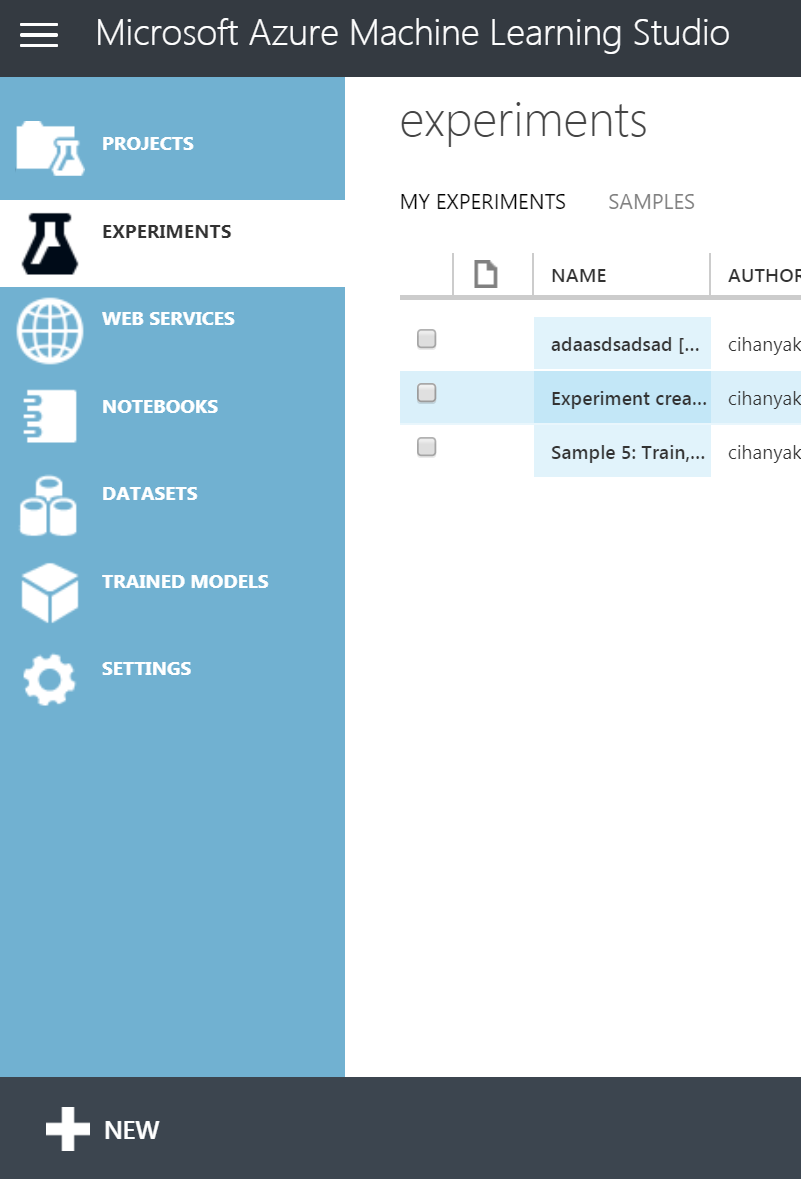
Peşinden açılan ekran ise tam bir bilgi küpü. Bu ekranda hazır halde bir çok deney örneği mevcut. Farklı çalışmalarınızda oldukça kopya çekeceğiniz bir ekran olduğunu düşünüyorum. Biz tur ile aynı adımları gideceğimizden boş bir örnek ile başlayacağız. Blank'ı seçip devam ediyoruz.
İlgili seçimi yaptığımızda yeni bir deney ortamı oluşturulmuş olacak. Ve bizi aşağıdaki gibi bir çalışma ortamı karşılayacak:
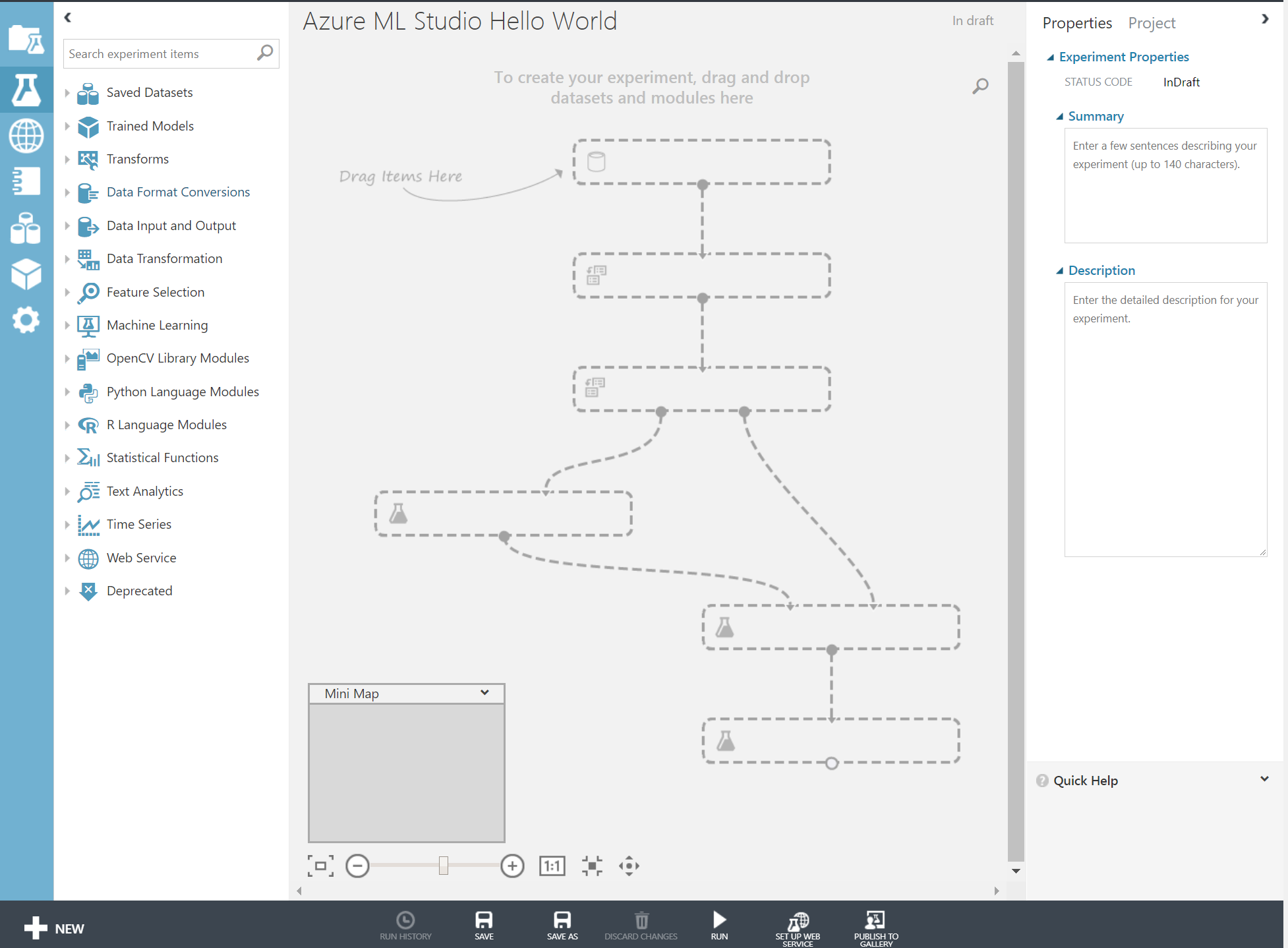
Bu resimde sol kısım Visual Studio'dan alışık olduğumuz üzere çalışma ortamına sürükleyebileceğimiz nesneleri barındırıyor. Her biri kategorilere ayrılmış durumda ve üst kısımda akıllı bir arama kutusu mevcut.
Orta kısım ise çalışma alanı, ben buna "tuval" diyeceğim. Sağ kısım ise o anda seçili olan nesnenin ayarlarını yapmamızı sağlıyor. Nasıl ki bir metin kutusunu sürükleyip forma bıraktıktan sonra onun rengini, yazıtipini ayarlıyoruz benzer şekilde tuval üzerine attığımız nesnelerinde ayarlarını buradan yapacağız.
Tuvale ilk olarak bir veri koymamız gerekiyor. Sol üst kısımdaki arama çubuğuna "income" yazıyoruz.
Karşımıza örnek bir veriseti çıktı. Kendisini sürükle bırak yöntemi ile sürüklüyoruz.
Ürün içindeki örnek veri setleri veri madenciliği, makine öğrenmesi konularında çok sık kullanılan veri setleri. Üzerlerinde defalarca çalışılmış olduklarından, örnek çalışmalara bakıp kendinizi geliştirebiliyorsunuz.
Peki, bu verinin içinde ne var? Bu görebilmek için kutucuğun altındaki çembere tıklıyoruz ve "Visualize" seçeneğini seçiyoruz. Bu bize çıktının görselleştirilmiş halini göstercek ve aşağıdaki gibi olacak.
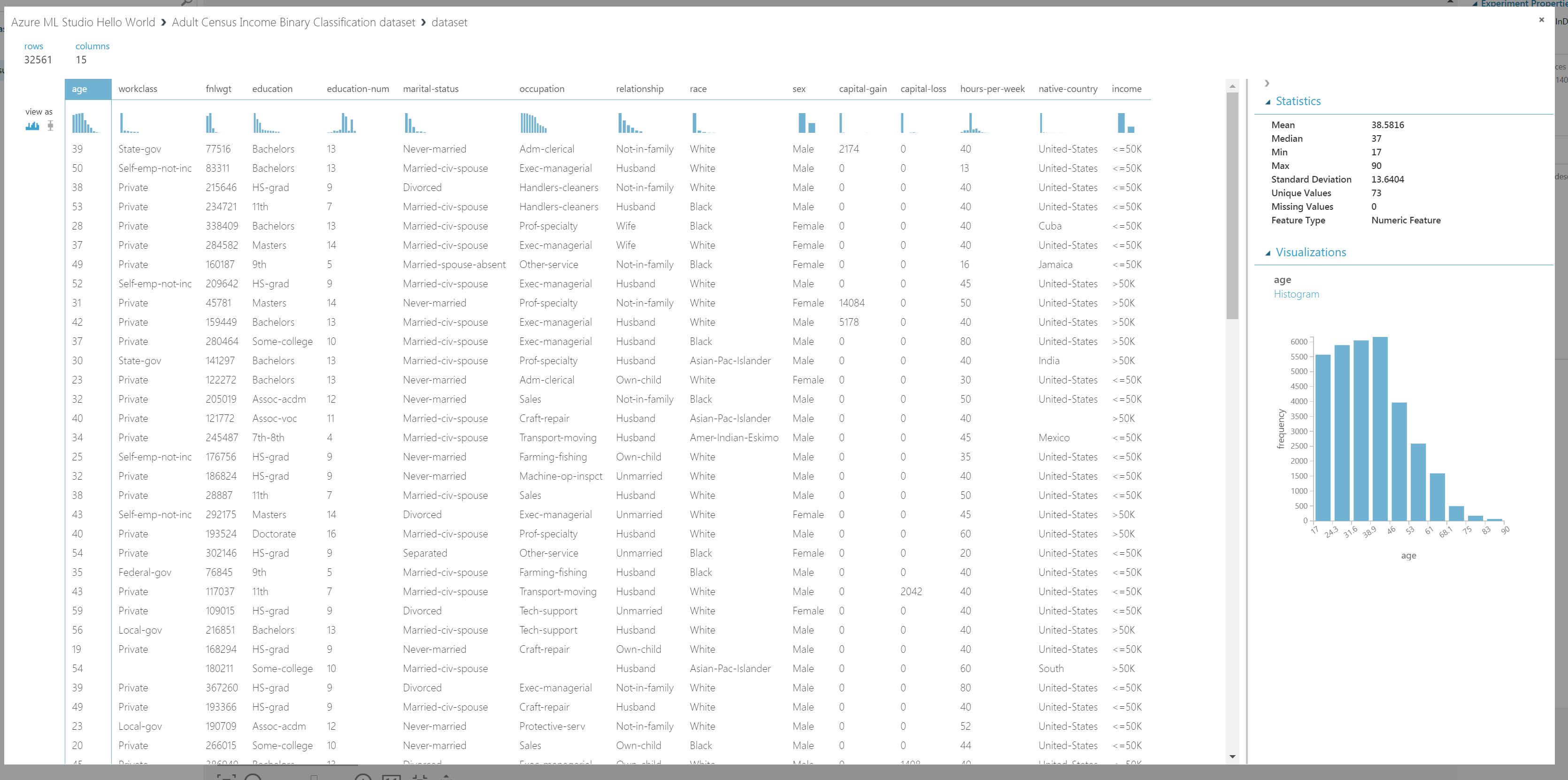
Bu ekran veri ile ilgili oldukça fazla bilgi vermektedir. Biraz inceleyelim. Sol üstten okumaya başladığımızda en temel bilgi olarak kayıt(row,record) ve nitelik (column,feature) adetlerini görüyoruz. Tablonun solunda ise "view as" şeklinde iki seçeneği olan bir bölge görüyoruz. Bu iki bölgeden solda olan, verilerin "histogram" şeklinde sunulmasını diğeri ise "box plot" şeklinde sunulmasını sağlıyor.
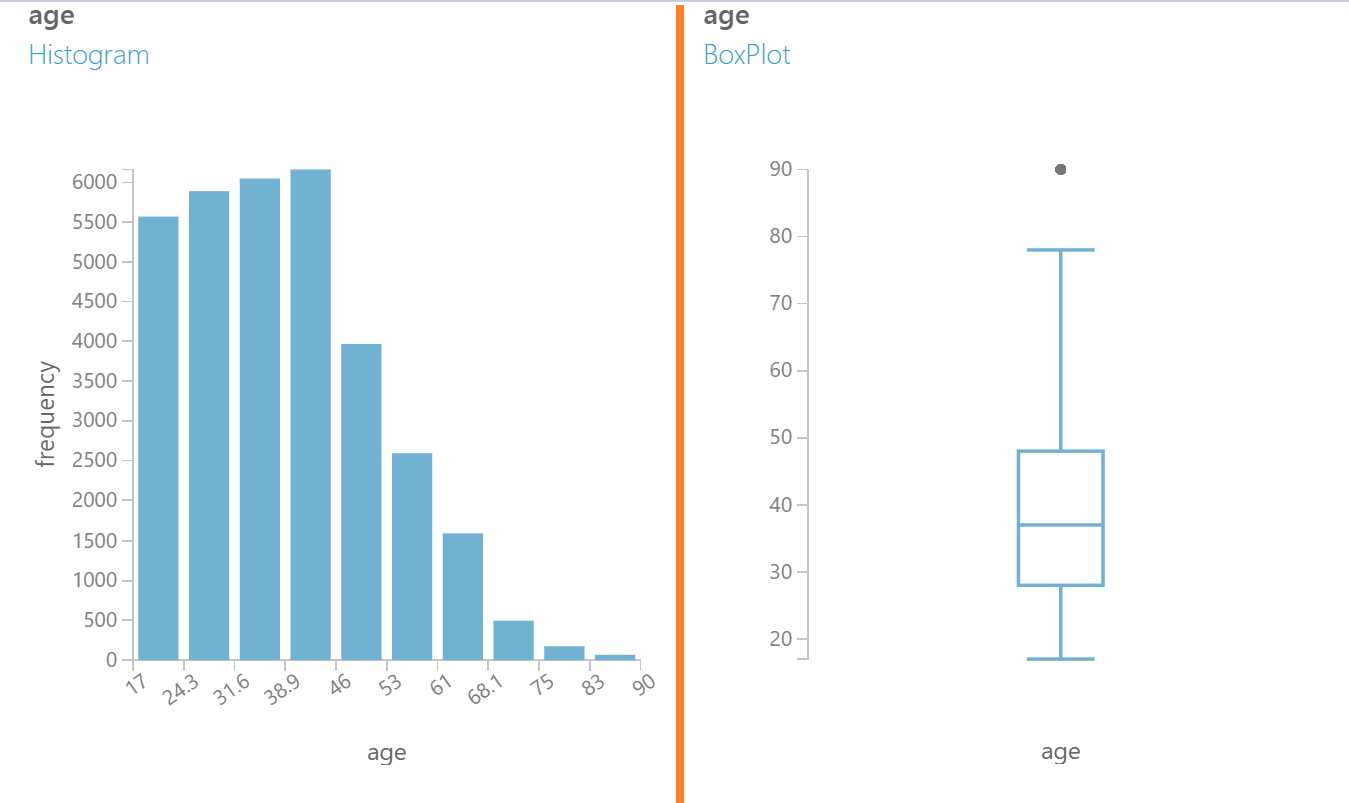
"Histogram" gösterimi hangi nitelikten kaç adet kayıt (satır) olduğunu gösterir. Yukarıdaki görselde soldaki grafikten anlaşıldığı üzere 40'lı yaşlarda oldukça fazla kayıt alınmıştır. "Box Plot" ise sayısal nitelikler için merkezi dağılımı ve sapan değerleri gösterir. Grafiğe bakarak ortalamanın 40 civarında olduğunu ve 40'dan yaşlı kişilerin 40'dan genç olanlardan fazla olduğunu ve bu veri için 80'den sonrasının sapan veri olarak alınabileceğini görebiliriz.
Merkezi dağılım ve sapan veriler ile ilgili daha önce yazmıştım. Merkezi dağılım ölçüleri.
Orta kısım tablo halinde verileri, sağ kısım ise istatistikleri (dağılım ölçütleri, eksik veriler gibi) sunmaktadır. Turun devamına geçmeden önce şu görsele bir bakın:

Buradan her bir nitelik için hızlıca yorumda bulunmak mümkündür. "age" yorumlanırken yaşlılara doğru bir kayma olduğu söylenilebilir. "workclass" için sınıflardan birinde oldukça fazla yığılma olduğunu söyleyebiliriz ki bu makine öğrenmesi için hoş değildir. "fnlwgt" de grafiğin üstündeki noktalar oldukça fazla aşırı değer olduğunu söylemektedir bu da öğrenme başarımını düşürebilir. Diğerlerinde de benzer yorumlarda bulunmak mümkündür.
Veri kalitesi ile ilgili şöyle bir yazım vardı: Veri Kalitesi
Gönül yukarıdaki yorumlara ilişkin veri üzerinde temizlik yapmak ister ama tur programından çıkmak istemiyorum. Hemen soldan "split data" şeklinde arama yapıyoruz ve aynı isimdeki nesneyi sürükleyip bırakıyoruz. Aşağıdaki gibi görüntümüz oluyor.
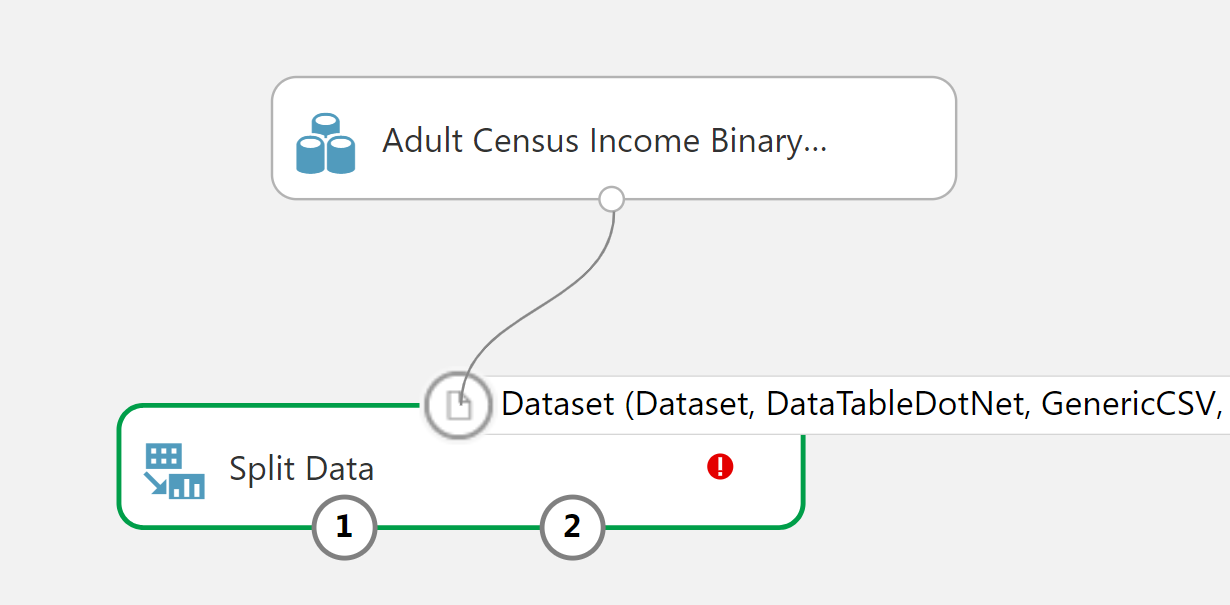
Bu görsel bize bir çok şey anlatıyor. Kutucuğun üst kısmındaki çember girdiyi alt kısmındaki çemberler ise çıktıları belirtiyor. Bir çemberin üzerinde imlecinizi tutarsanız size o girdi veya çıktının türünü söyleyecektir. Bunu C# daki metotlara benzetebilirsiniz. Metotları çağırırken nasıl ki uygun türden parametre vermek gerekiyorsa burada da aynı durum söz konusu. Bu sebeple nesnelerin çıktılarını başka nesnelerin girdilerine bağlarken türlerin uyması gerekir. Fark ettiyseniz, kutucuğun içerisinde kırmızı bir ünlem bulunuyor. Bu da o kutu ile ilgili bir hata olduğunu belirtiyor (eminim çok şaşırmışsınızdır). Hatanın ne olduğunu bilmek isterseniz, imleci ünlemin üzerine getirip okuyabilirsiniz. Ürünü kullandıkça hataların çoğunun tuvali kaydetmediğinizden veya çalıştırmadığınızdan kaynaklandığını fark edeceksiniz.
"Split Data" adı üzerinde veriyi iki parçaya bölmekte. Öğrenme algoritmasını test edebilmek için elimizdeki verinin bir kısımını eğitimde kullanmayıp başarımı test etmek için saklamak gerekir. Fakat bu saklanacak verinin ayrılmasını ML Studio kafasına göre değil bizim belirteceğimiz parametrelere göre yapmaktadır. Parametreleri belirtmek için kutuyu seçip sağ tarafa geliyoruz:
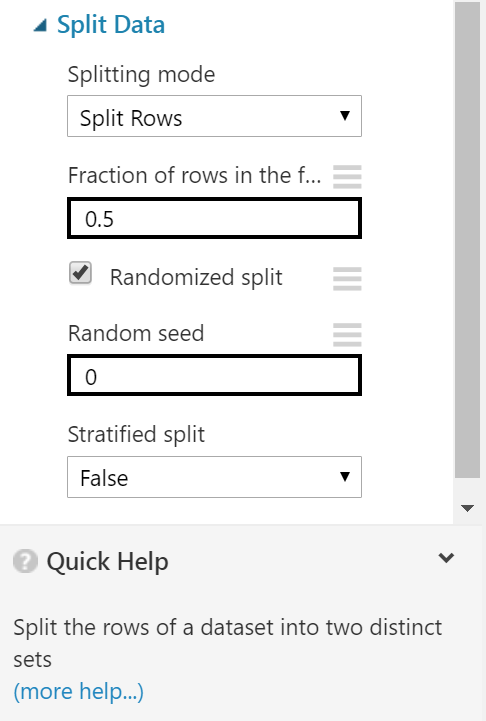
Burada bölme işleminin nasıl olması gerektiğini seçiyoruz. Bölme oranı nasıl olacak, rastgele mi olacak belirli kurallar dahilinde mi olacak gibi ayarları yapıyoruz. En altta ise bu kutu ile ilgili dokümantasyona ulaşabiliyorsunuz. Tüm detaylar dokümantasyonda mevcut. Biz oran olak 0.7 gireceğiz bu nesnenin soldaki çıktısının oranını belirtiyor aynı zamanda. Ayarları yapıp, kaydedip buraya kadar olan süreci çalıştırıyoruz.
Azure ML Studio'da sonradan sıkıntı yaşamamak adına sürekli "save" ve "run" komutlarını çalıştırmanızı öneririm. Bazı kutucukların ayarları kendisine input olarak bağlanmış kutucukların sonuçlarına göre olabiliyor. Bu durumda eğer input konumunda olan bir kutu daha önce çalıştırılmamış ise bağlantılı kutunun ayarlarının tamamına ulaşamıyorsunuz.
Sıradaki adımda "eğitim" işini yapacağız. Bunun için "Train Model" araması yapıyoruz. Ve ekrana ekliyoruz.
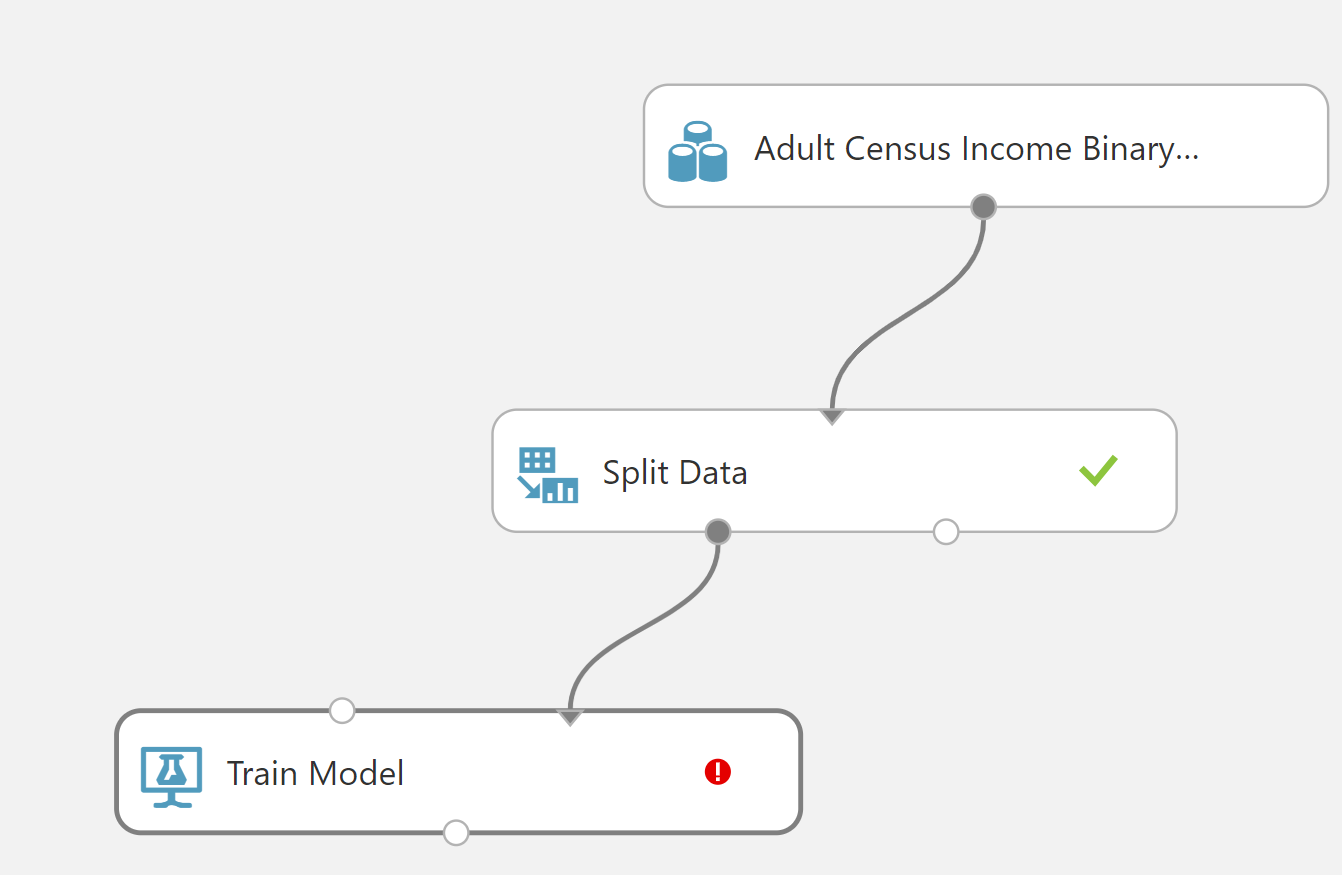
"Train Model" kutusunun 2 girdisi 1 çıktısı bulunmakta. Girdilerden sağ tarafta olan üzerinden öğrenme yapılacak veriyi, sol tarafta olan ise öğrenme algoritmasını kabul ediyor. Çıktı ise öğrenilmiş modeli barındırıyor.
Bir öğrenme algoritmasını eklememiz gerekiyor. Bizim amacımızda A veya B gibi iki durumdan hangisine daha yakın olduğunu bulmak olduğundan "binary" sınıflandırma yapmamız gerekiyor. Bunun için "Two class" veya "Binary" şeklinde aramalar yapabiliriz neticesinde bize aşağıdaki gibi sonuçlar getirecektir.
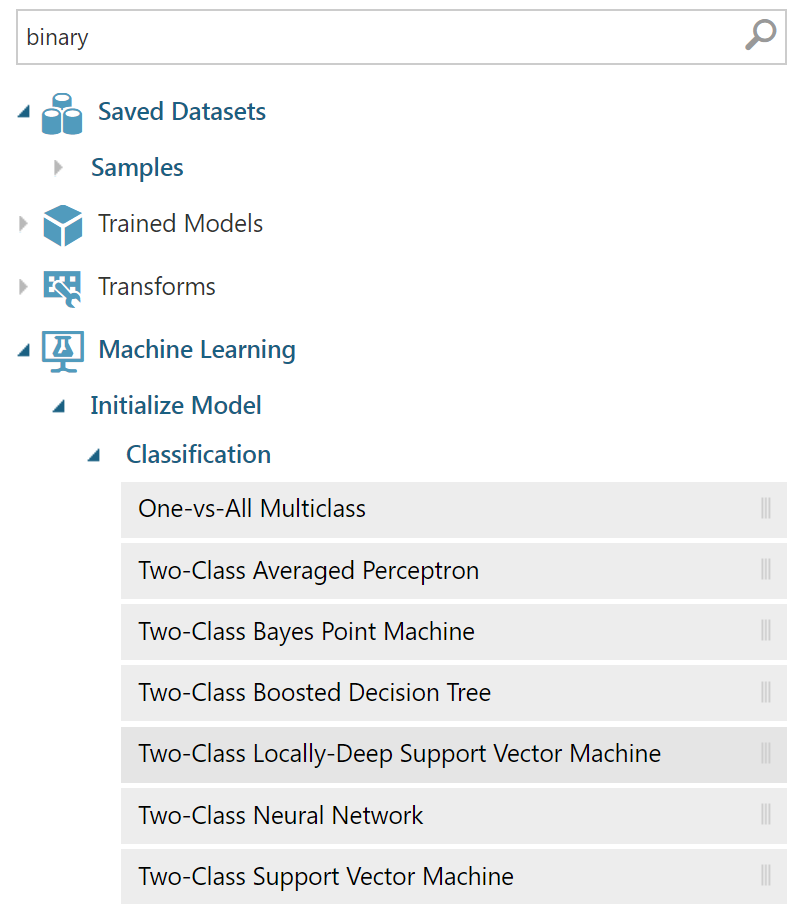
Buradaki algoritmaların bir çoğunu çalışmamızda kullanabiliriz. Turdan şaşmamak adına "Two Class Boosted Decision Tree" algoritmasını seçip bağlantıları yapıyoruz. Bağlantıları yaptığımızda modeli oluşturamıyor olacağız çünkü neyi tahmin etmesi gerektiğini söylemedik. "Train Model" nesnesinin özelliklerine gelip "Launch column selector" a basıyoruz.
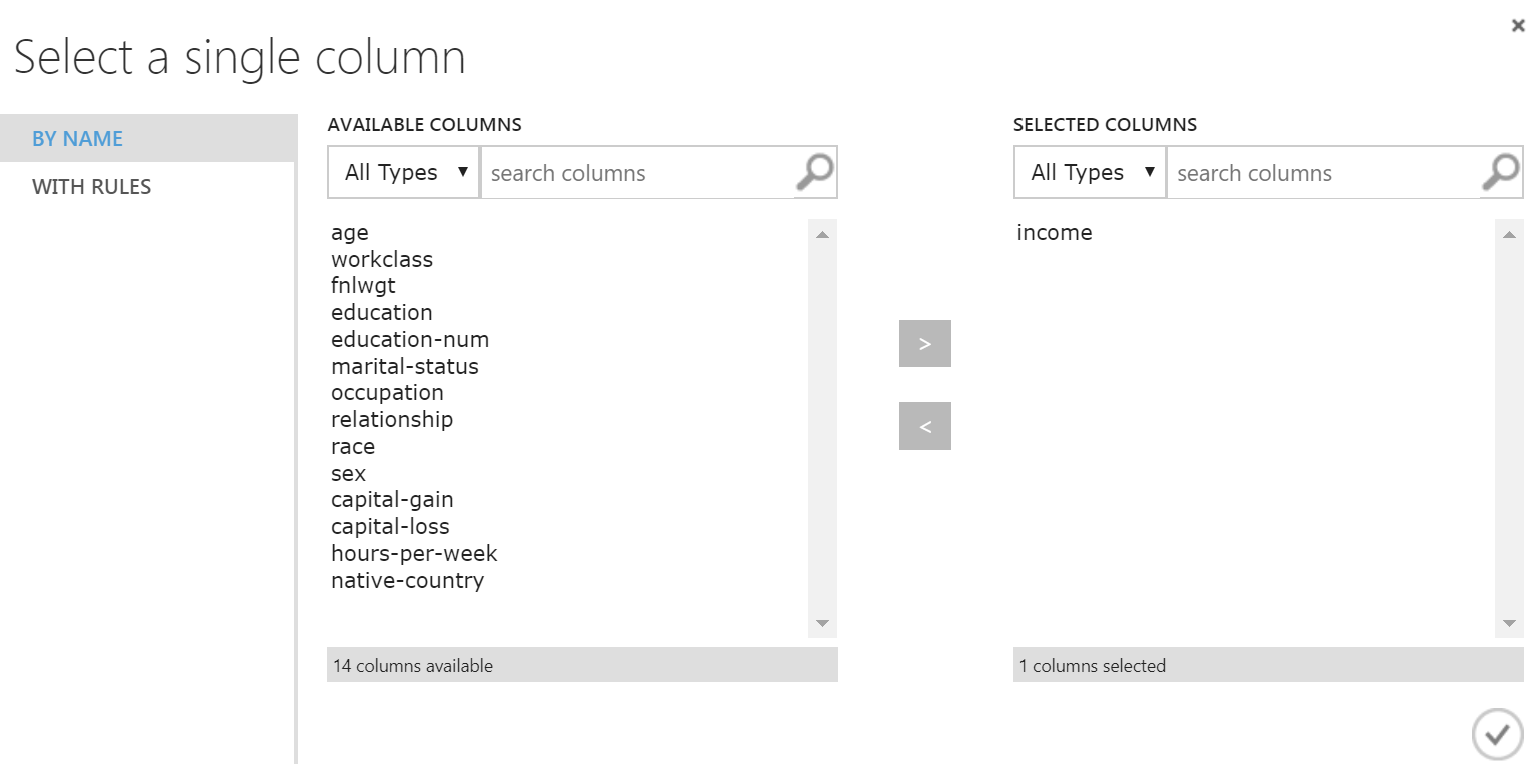
Açılan pencereden "income" niteliğini seçiyoruz. Eğer sol tarafta nitelik adları gelmemiş ise "Split Data" kutusunu çalıştırmamışsınız demektir. "Split Data"'ya kadar olan kısmı seçip "Rul Selected" demeniz yeterli olacaktır.
Buraya kadar, soldan arama yap, sağa sürükle bırak, bağlantıları yap, ayarları yap konseptine ısınmışsınızdır diye düşünüyorum. Modeli oluşturup modelin nasıl göründüğüne bakmanızı isterim. Biz bir karar ağacı algoritması kullandığımız için modelimiz aslında bir çok if/else bloğundan oluşuyor. Modelin çıktısının görselleştirmesine bakacak olursanız ağaçları görebilirsiniz.
Model oluştuğuna göre, elimizdeki test verisini bu model ile değerlendirebiliriz. Bunun için bir skorlama "scorer" nesnesine ihtiyacımız olacak. "Score model" aramasını yapıp ilgili nesneyi tuvale atıp, uygun bağlantıları yapalım. Bu arkadaş çalıştıktan sonra test verilerinin sonuna sırasıyla "Scored Labels" ve "Scored Probabilities" adlarında 2 yeni kolon eklemiş olacak. Böylece test verisindeki her bir satır için yapılan tahmini görebiliyor oluyoruz. Bu tahminlerin bir kısmı doğru bir kısmı yanlış olacaktır. Doğru ve yanlış tahminlere göre yapılan işin ne kadar başarılı olduğu hakkında fikir sahibi olabiliriz.
Skorların değerlendirilmesi için gereken nesneyi "Evaluate Model" şeklinde aratıp ekliyoruz. Sonuç aşağıdaki gibi olacak.
Değerlendirmenin görselleştirilmiş hali ise aşağıdaki gibi olacak.
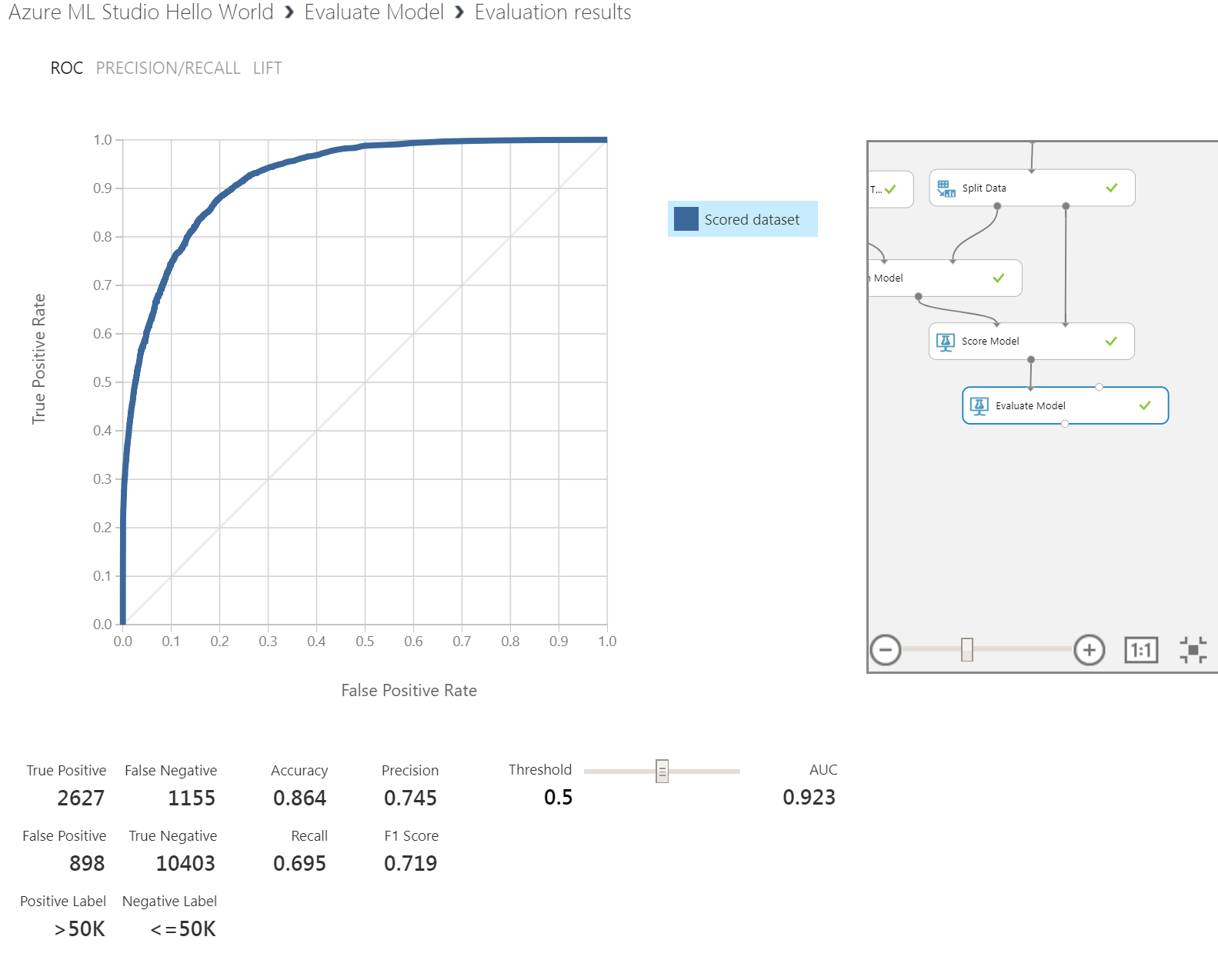
İşin en can alıcı kısmına geldik. "Bu model ne kadar başarlı?" sorusunun yanıtını vermeye çalışacak ekran bu. Eğitim ve test verisini rastgele böldüğümüzden buradaki sonuçlar sizde görselde olduğundan farklı çıkabilir. Peki buradaki sayılar ve üstteki grafik neyi ifade ediyor?
Sol üstten başlayalım. Burada bir eğri olan grafik görüyorsunuz. Bu eğrinin adı "ROC" açılımı ise "Receiver Operating Characteristics". Bizim modelimiz ikili sınıflandırma türünden idi hatırlarsanız. Yani her satır veri için iki olasılıktan birisine karar verilmesi gerekiyor. Olasılıklardan birisini pozitif diğerini negatif olarak değerlendiriyoruz. Bu senaryo için 50bin üzeri kazanım pozitif, altı ise negatif olarak değerlendirilmiştir. Test edilen satır için hesaplanan olasılık değerimiz 0.5 in üzerinde çıktığında gelirin 50bindan fazla , altında çıktığında ise 50binden az olduğunu söyleyebiliriz. Bu 0.5 eşik değerimizdir. Eğrimiz ise bu eşik değerinin hareket ettirilmesi ile oluşmaktadır. Ben eşiği 0 kabul edersem tüm satırları negatif, 1 kabul edersem pozitif kabul etmiş olurum. Bu eşiği 0 ile 1 arasında hareket ettirdikçe her bir eşik değeri için farklı doğru tahmin sayısı elde ederim. İşte grafiği de bu mantıkla okumamız gerekiyor. Eğrinin sol üst koşeye oldukça yakın çıkmasıni hedefliyoruz.
Grafiğin hemen altında bir tablo bulunuyor buradak ilk 4lü olan "True Positive","False Negative", "False Positive" ve "True Negative" kısmına "Confusion matrix" (hata/karışıklık matrisi) adı verilmektedir. Bu kısım aslında A olan ve A diye tahmin edilmiş ("True Positive") olanlar, aslında A olan ama B olarak tahmin edilmiş olanlar ("False negative") gibi dört durumun dağılımını vermektedir.
Bunların yanında bulunan "Accuracy,Precision,Recall" üçlüsü ise karışıklık matrisindeki değerlerin bir birileri ile işleme girmeleri ile hesaplanmaktadır. "F1 Score" ise precision ve recall'un harmonik ortalaması alınarak bulunmaktadır.Başarılı bir sınıflandırma için buradaki tüm sayıların 1 e yakın olması beklenir. Değerlendirme ile ilgili ayrıca detaylı bir yazı hazırlayacağım için kısa kesiyorum.
En sağda bulunan kaydırma çubuğu ise eğrinin çizmek için kullandığımız eşik değerinin farklı değerlerindeki sonuçları görmemizi sağlamaktadır. AUC değeri ise ROC eğrisinin altında kalan alanı vermektedir. Bu değer 1'e yaklaştıkça modelin başarılı olduğuna dair fikir vermektedir.
Altta yer alan ızgarada ise farklı olasılık değer aralıkları için ölçüm değerlerini vermektedir.
Sonuçları yorumlayacak olursak, iki değer bizim için belirleyici olacaktır. AUC değeri benim çalışmamda 0.923 çıkarak oldukça başarılı bir sonuç vermektedir. Fakat, F1 Score değeri 0.719'dur bu da modelin kullanılabilir olduğunu ama çok da yüksek başarıma sahip olmadığını söylemektedir. Peki bu ikisi neden bu kadar farklı çıktı? Çünkü elimizdeki verideki pozitif örneklerle negatif örnekler arasında arasında adet olarak uçurum bulunmaktadır. Bunu şöyle düşünebilirsiniz, 100 kişiden 2 kişi hasta olsun ve sınıflandırıcı 99 kişinin sağlıklı 1 kişinin ise hasta olduğu sonucuna varsın. Böyle bir senaryoda AUC oldukça yüksek çıkarken F1 Score oldukça düşük çıkacaktır. Bu değerler için en düşük değerin 0.5 olduğunu da hatırlatırım. 0.5 ölçümü yazı tura atmak ile eş değerdedir.
Serbest Gezi
Turu tamamladığımıza göre biraz da kendimiz gezebiliriz. Hedefimiz başarımı arttırmak. Veri ön işleme ile başlamak iyi olurdu ama ben öncelikle algoritma ayarlarını kurcalamak istiyorum. Kullandığımız algoritmanın ayarları aşağıdaki gibidir.
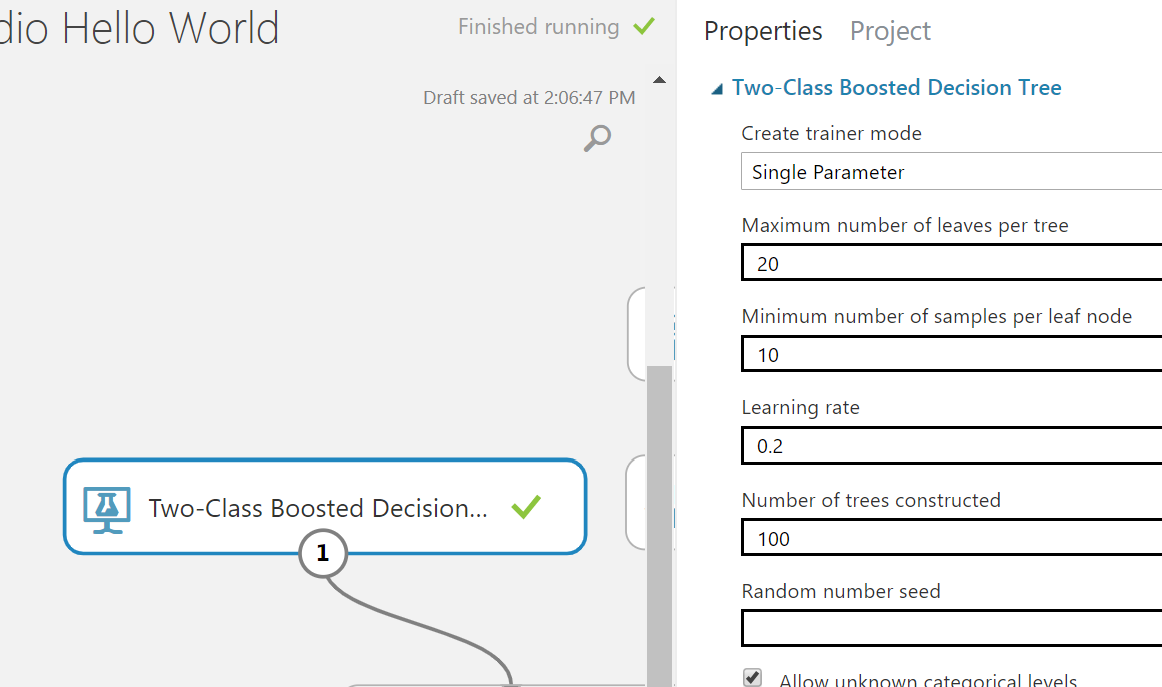
Burada farklı sayılar yazıp sonuçlara bakmak lazım. Fakat tek tek denemek zahmetli olacağından bu deneme işini studio'ya bırakmak istiyorum. Öncelikle "Train Model" kutusunu tuvalden siliyorum. Bunun yerine "Tune model hyperparameters" kutusu ekliyorum, uygun girdileri ve çıktıları bağlayıp ayarlarına geliyorum. Burada 2 ayar yapacağım. Birincisi, kaç farklı deneme yapacağına ilişkin olan "" ayarı olacak. Bunu 100 olarak belirtiyorum. İkincisi ise en iyi yapmaya çalışacağı başarım metriği olacak, onu da "F Score" olarak ayarlıyorum. Ayarlar aşağıdaki gibi olacak:
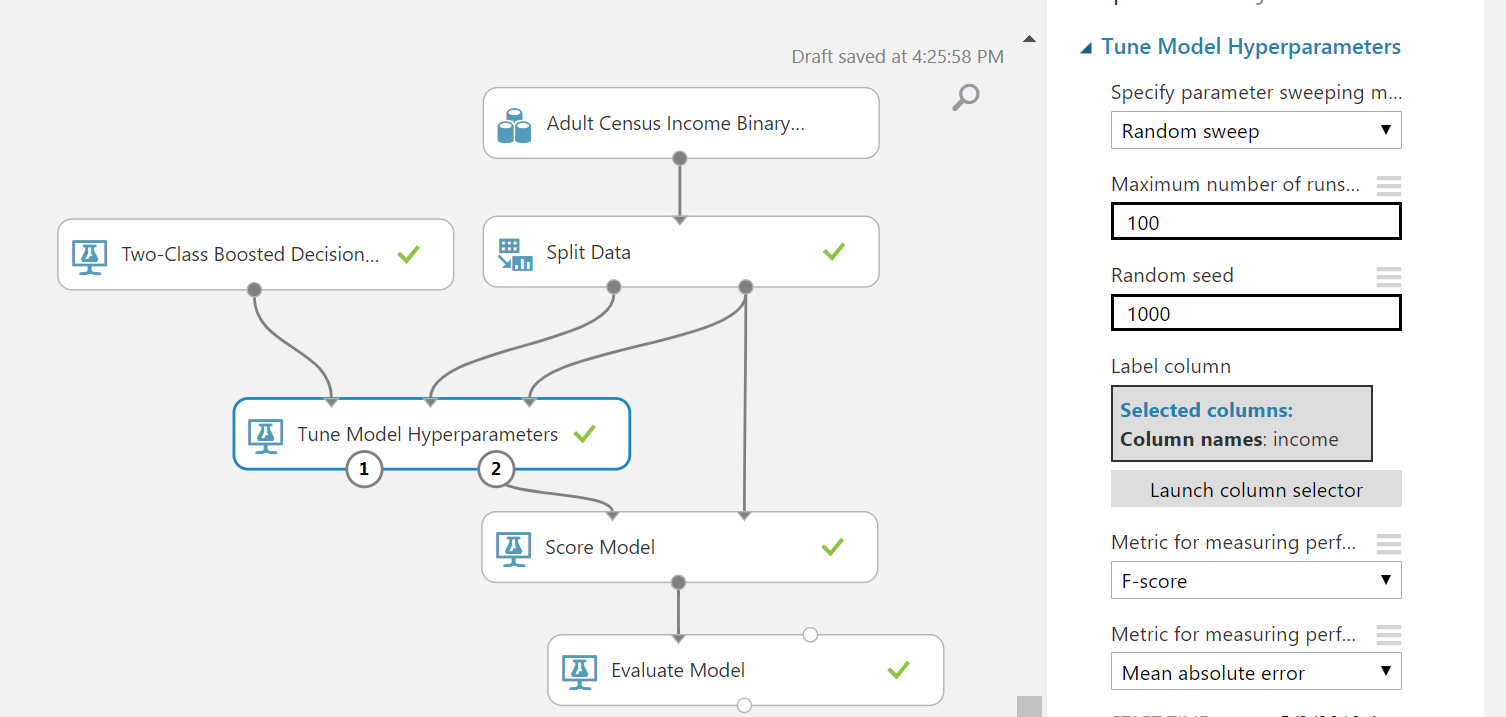
Çalıştırıp, kahve almaya gidiyoruz. Arkadaş 100 defa çalışıp en uygun değeri bulmaya çalışacak ve sonuca baktığımızda iyileşmeyi görebiliriz.

F1 Score değerimiz 1 puan artarak 0.72 değerine ulaşmış oldu. İşlem rastgele olduğundan sizde daha düşük veya daha yüksek değerler çıkabilir. Zamanınız bolsa deneme sayısını yükseltebilirsiniz. Ben bazen 1000-2000 deneme yaptırıyorum. Açıkçası bu denemeleri dağıtık şekilde çok hızlı yapabilecek olmasına rağmen yarım saatlik beklemeler oluyor. Parasını versek hızlansa diyeceğim ama o da yok.Fazla serzeniş yapmadan konumuza dönersek, evet değerler ile oynadı başarımı arttırdı ama hangi değerler ile bunu sağladı? Bunu görebilmek için "Tune model hyperparameters" kutucuğunun boştaki çıktısına bakmamız yeterli olacaktır. Bu çıktı bile eğer deneme sayısını 1000'lerce yaparsanız bir veri madenciliği problemine dönüşmüyor değil.
Bu yazıyı fazla uzatasım yok. Konuları başka yazılara dağıtmak istiyorum. O sebeple son bir geliştirme ekleyeceğim. Son örneğimiz işlemleri biraz hızlandırmak adına bir adım olacak. Elimizdeki verinin 15 nitelikten oluştuğunu hatırlıyorsunuz. Bunun 14 ünü kullanarak sonuncusunun ne olduğunu tahmin etmeye çalışıyoruz. Peki bu 14 niteliğin hepsine ihtiyacımız var mı? Daha az nitelik kullanarak tahminde bulunamaz mıyız? Bu üzerinde çalıştığımız veriye göre değişir. Bazen tek bir nitelik bile tahmin için yeterli iken bazen 14ü de sonuç üretmiyor olabilir. Bu niteliklerden ikisi aynı ya da oldukça benzer bilgiye sahip olabilir. Benim sık olarak yaş ve doğum yılı örneğini veriyorum. Her ikisi de farklı değerler içersede aynı bilgiyi içermektedir. İkisini birden öğrenmede tutarsanız, modeliniz için kişilerin yaşı daha ayırt edici hale gelmiş olur ki bunu istemezsiniz.
Nitelik azaltma için "Filter Based Feature Selection" isimli nesneyi tuvale bırakıyorum. Ve aşağıdaki resimdeki gibi ayarlıyorum.
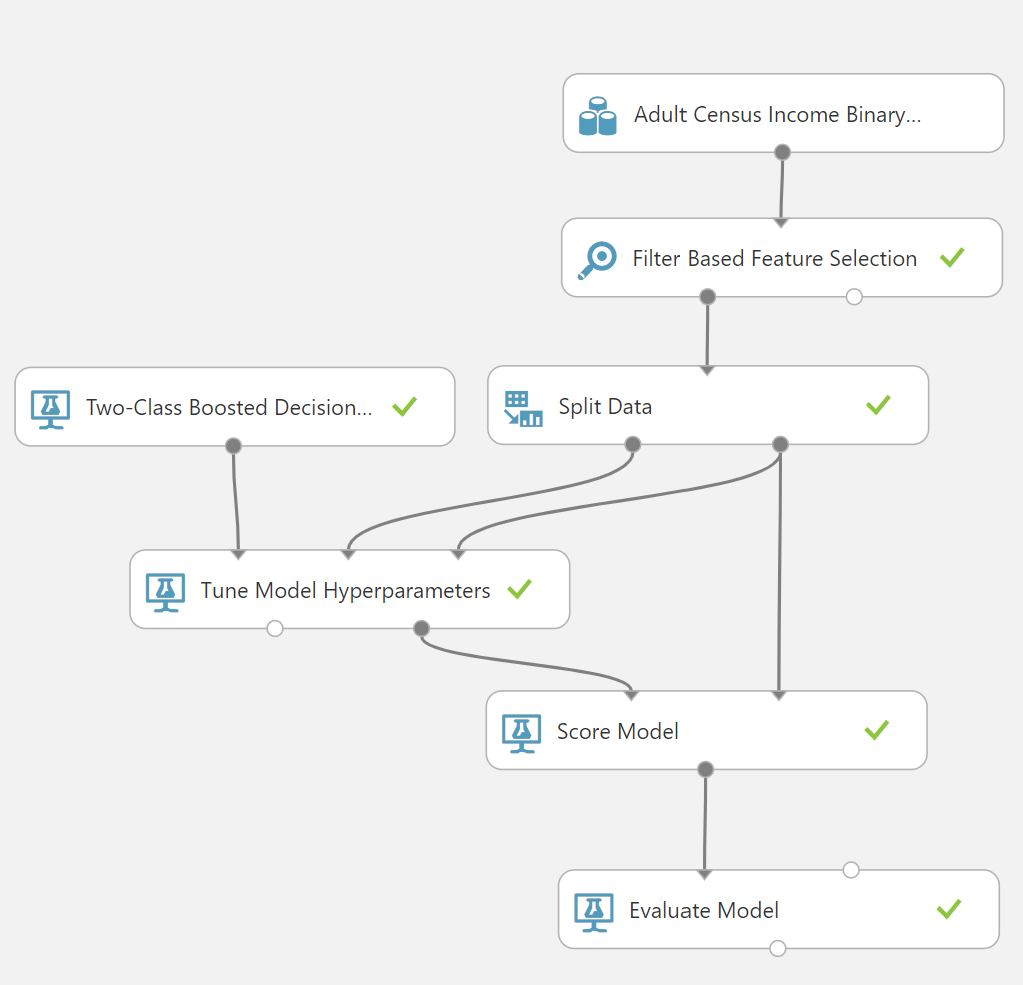
"Mutal Information" ile ortak bilgileri temizlemeye çalışıyorum. 10 niteliğe düşürmesini ve "income"un bulmak istediğim nitelik olduğunu söylüyorum. Mevcut ayarlar ile başarımda ve hızda hemen göze çarpan bir değişiklik var mı diye bakmak istiyorum. Nihai tasarım aşağıdaki gibi olacak.
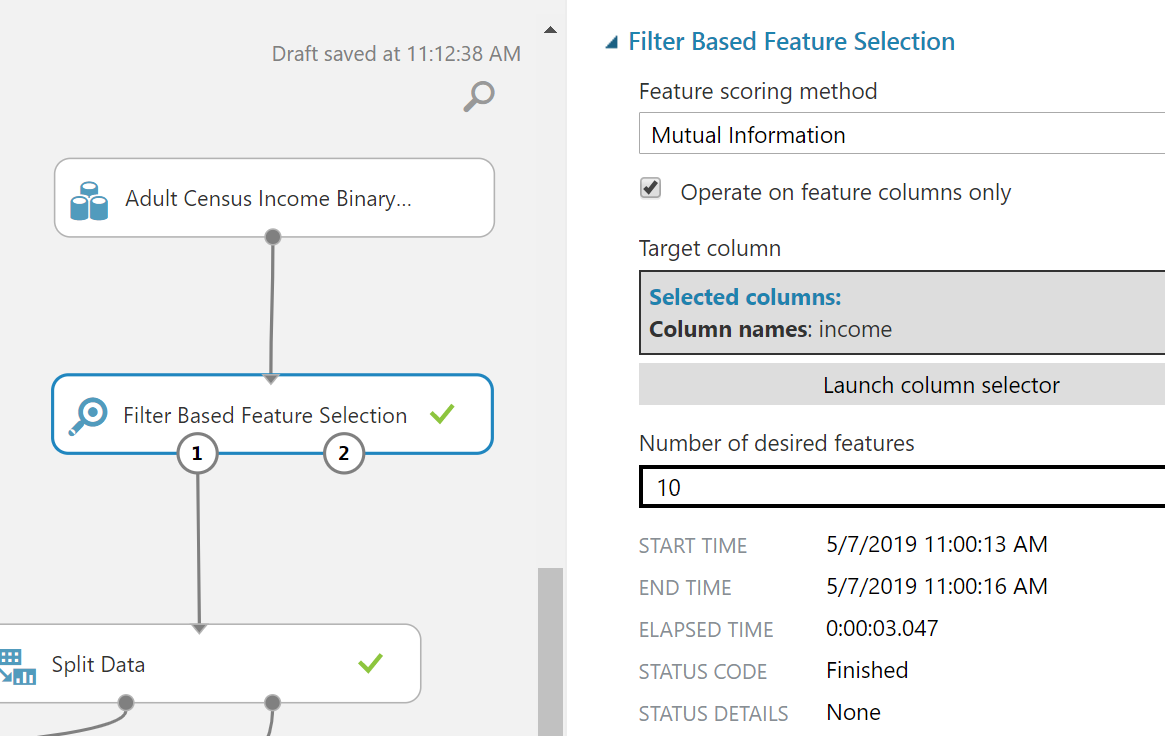
"Tune model hyperparameters" kutusunda deneme sayısını 1000 yaptığımda başarımda kayda değer bir değişiklik görmedim. 0.1 lik farklar kullandığımız algoritmalar rastgele değişkenler ile çalıştığından pek anlamlı değiller. Hız konusunda ise 30dk süren optimizasyonun 20dk sürdüğünü gördüm. Fakat arada 10dk olması bir artış gösterse de bunun anlamlı olabilmesi için farklı zamanlarda bir çok deneme yapmak gerekir. Sonuçta sistem Azure üzerinde çalışıyor ve performansı etkileyen o kadar çok faktör olabilir ki süper izole bir ortamda çalışmadıkça emin olmak zor. Ama işe algoritma karmaşıklığı açısından bakarsak tek işlemcili ortamda hızlanma olmasını zaten bekliyorduk.
Eve dönüş
Azure ML Studio epey büyük bir ürün, veri üzerinde hızlıca çalışmanızı ve web servisler çıkartmanızı sağlıyor. Fakat arayüz sanki az kutucukla çalışmak için yapılmış gibi. Mesele biraz büyüdü mü arap saçına dönüyor. Bir anda kutuları muntazam dizmeye çalışırken buluyorsunuz kendinizi. Python,R desteği güzel ama "F# nerede kuzum?" demeden alamıyorum kendimi. Açıkçası bu ürünle tanışınca F# öğrenmeye devam etmekten vazgeçtim. Microsoft kendi ürününe üvey evlat gibi davrandığına göre çoğunluğun olduğu Python, R gibi dillere geçmekte fayda var. Python veri ile uğraştığınız her yerden çıkıyor. Bunun için de VeriDefteri.com 'dan en düzgün başlangıç eğitimine ulaşabileceğinizi belirtmek isterim.
Sonraki yazılarda kendi problemlerimizi çözerek ürünü daha iyi tanımaya çalışacağız. Teşekkürler.

Çook Teşekkür Ederim. Gerçekten benim için çook faydalı bir yazı oldu. Umarım Azure Makine Öğrenmesi üzerine daha çok yazılar yazarsınız.
Hevesle bekliyor Olcağım.