Azure ML studio ile yapay sinir ağları bir kaç kez sorulunca konu sırasını bırakıp aradan bir giriş konusu oluşturayım dedim. Bu yazıda yapay sinir ağları ve derin öğrenmenin ne olduğundan bahsetmeyeceğim hem bunun sıfırdan C# ile kodlanması konusunda bir yazı hazırlayacağım hem de temel konseptleri hemen her yerde bulmak mümkün.
Bu aralar üzerinde sık çalıştığım veri ile devam edeceğim. Kaliforniya ev fiyatları. Kendisini https://www.kaggle.com/camnugent/california-housing-prices adresinden edinebilirsiniz. Peki ama edindikten sonra bunu Azure ML Studio'ya nasıl aktaracağız? İlki daha önceki örneklerde yaptığımız gibi kopyala yapıştır mantığı olabilir. Ama bu veriseti ile daha çok çalışacağımızdan el altına olmasında fayda var. AMLS (Azure ML Studio'yu bu şekilde kısaltacağım) içerisine bu veriyi yüklemek için "DataSets" bölümüne geliyoruz ve kocaman "new" düğmesine basıyoruz.
FROM LOCAL FILE deyip CSV dosyasını yüklüyoruz. Verimiz şöyle:

🎻Büyük dosyaların upload işlemi uzun süreceğinden doğrudan ZIP biçiminde yükleyebilirsiniz. Bu durumda dosyayı kullanmak için deney tahtasında UNZIP işlemi gerçekleştirmeniz yeterli olacaktır.
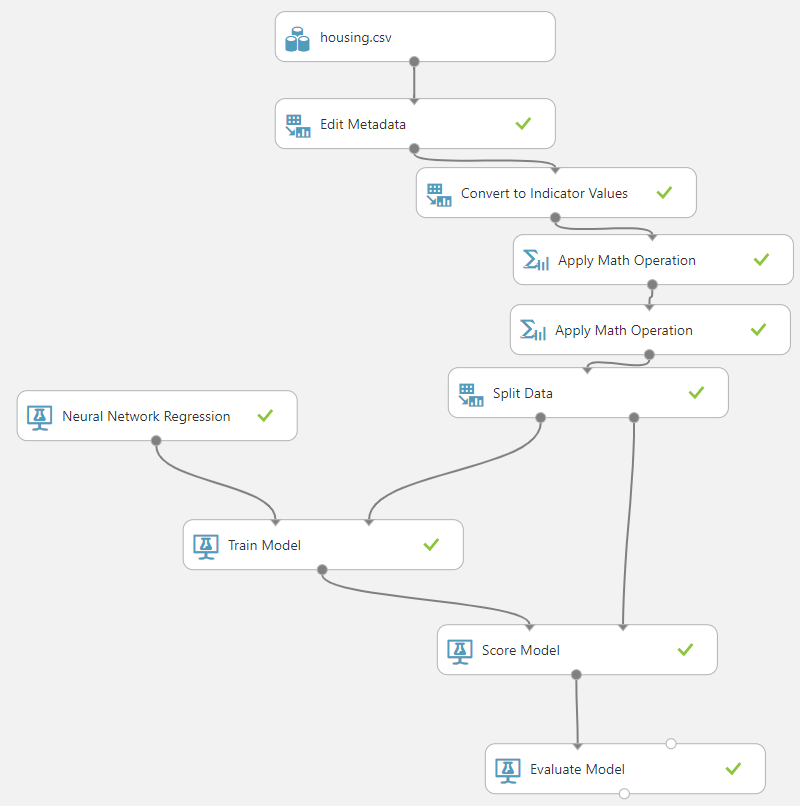
Ardından her zamanki gibi yeni bir deney başlatıp verisetini tuvalin üzerine bırakıyoruz. Buradan sonrasında tüm tuvalin görünümünü şu hale getiriyoruz. Tabii siz benden daha düzenli olacaksınızdır.
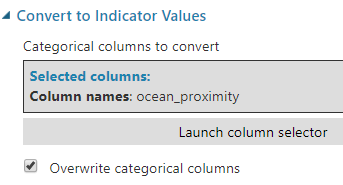
Convert to Indicator Values modülü kategorik değişkenlerimizi kolonlara ayırıp bu değere sahip olan satırlarda ilgili kolonun değerini 1, olmayanları 0 yapıyor. Buna "One Hot Encoding" adı da verilmektedir. Örneğin "cinsiyet" gibi tek bir kolon "kadın" ve "erkek" şeklinde iki kolona ayrılıp kadın birisi için aynı sırayla 0 ve 1 değerlerini alacaktır. Bunun sebebi erkek ve kadın olmak arasına bir matematik, uzaklık ilişkisinin olmamasıdır. Algoritmanın bundan etkilenmesini istemiyoruz.
Veri bu işlemin ardından şuna dönüyor:

Apply Math Operation modülü adından da anlaşılacağı üzere bir matematik işlemini bir kolona uygulamak için kullanılıyor. Peki biz bunu neden kullanıyoruz? Azure ML Studio içerisindeki NN Regression etiket kolonu üzerinde normalizasyon yapmadığı için yüksek değerlerde hep aynı değeri üretmekte. Bunun önüne geçebilmek için bu kolonu normalize edebiliriz fakat bu durumda da çıktının tekrar eski haline çevirmesinde zorlanırız. Bunun için en küçük değeri çıkartıp (en büyük değer - en küçük değer)'e bölerek bu işlemi hallediyoruz. Model için web servis oluşturduğumuzda ise bunun tersini yapıp çarpmamız yeterli olacaktır.
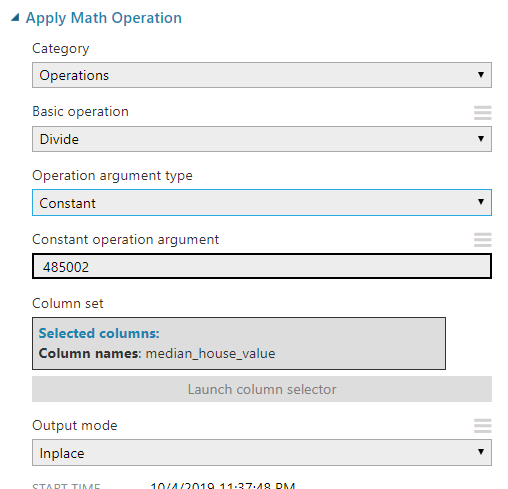
Verideki değişim şöyle:
Neural Network Regression Gelelim asıl yazının konusu olan kısıma. Benim deneyimdeki ayarlar şu şekildeydi:
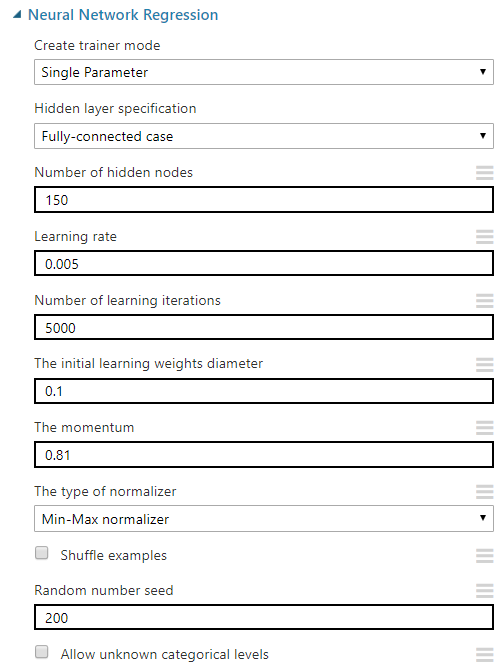
Trainer Mode Otomatik iyileştirme için Multi Parameter olarak ayarlanabiliyor biz örneğimizde Single Parameter olarak ilerleyeceğiz.
Hidden layer specification Gizli katmanın türünü soruyor. Klasik yapay sinir ağları için Fully-connected case dememiz yeterli. Bu durumda tek gizli katmanlı klasik yapı oluşturulacaktır. İkinci seçenek olan custom da ise tüm sinir ağını modelleme imkânına kavuşuyor oluyoruz. Derin ağlar, resim işleme vb. buradan yapılacak. Burada tanımlama için görsel bir araç yok Net# dilini kullanacağız.
Number of hidden nodes Tek gizli katmanlı klasik yapıda gizli katmanın kaç parçadan oluştuğunu belirliyoruz.
Learning rate Öğrenme işlemi için gereken adım açıklığı diyebiliriz. Çok geniş tutarsak en iyi değerden uzaklaşabiliriz. Çok küçük tutarsak hem daha çok zaman alacaktır hem de aslında en iyi değer olmayan bir değere takılıp kalabiliriz.
Number of learning iterations İyileştirme işleminin kaç tur yapılacağını belirtir. İlk sonuçlarda düşük, sonrasında yüksek tutmakta fayda var.
The initial learning weights diameter Ağırlıkların ilk değerlerini buradan ayarlıyoruz.
The Momentum Adım adım sonuca yaklaşırken bizi aslında hatalı olan bir değerde takılıp kalmaktan kurtaran bir değer. 0 ile 1 arasında bir değer veriyoruz. Deneye yanıla iyileştirebilirsiniz.
The type of normalizer Niteliklerin normalleştirilmesi için kullanılacak yöntem. Etiketin normalleştirilmediğini yukarıda belirtmiştim. O işlemi biz kendimiz yapıyoruz.
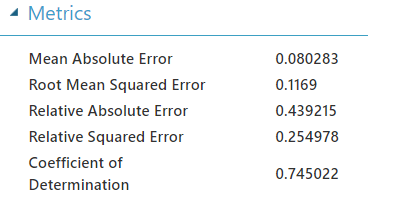
Tüm bu işlemleri yaptığımızda başarıma bir bakalım.
$$R^2$$ değeri ~0.745 daha önce aynı veri ile yaptığımızın altında ve çok daha zaman aldı. Gelecek yazılarda işin biraz daha derinlerine inmek üzere.